Qué estamos haciendo (II)
El gran libro de la naturaleza está escrito con símbolos matemáticos
No pensaba que iba a escribir otra entrada tan rápido1, pero, por supuesto, me he embarcado en otra aventura estas vacaciones. En lugar de descansar o hacer todas las tareas que tenía pendientes me he puesto a programar. Aunque en realidad no he programado mucho, la verdad.
Bueno, cuéntanos, ¿qué proyecto vas a abandonar esta vez?
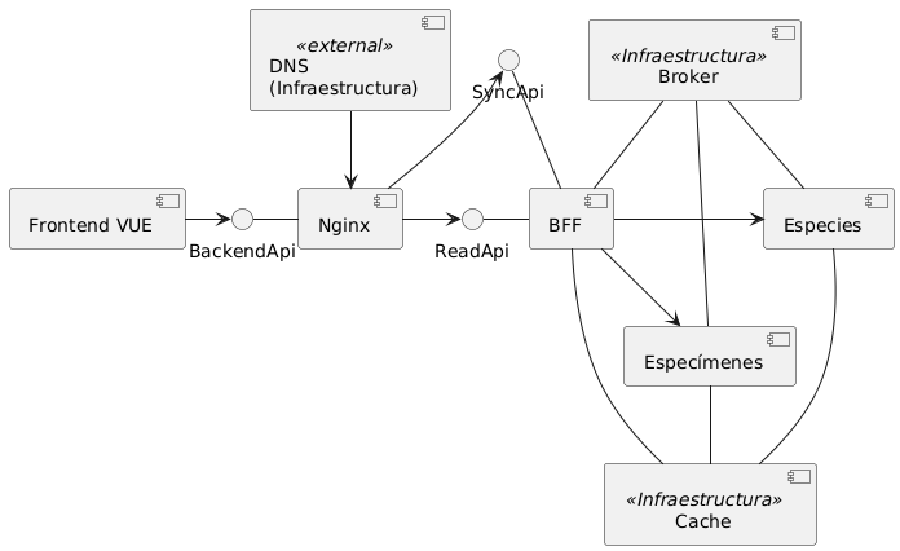
Bueno, ahora que tengo más plantas —una más, en concreto—, había decidido empezar algo que lleva tiempo rondándome la cabeza: una aplicación para las plantas. La idea en principio era sencilla, y debería ir escalando poco a poco. Un registro de especies, y otro de especímenes. El primero sería la ficha de distintas especies (nombre científico, cuidados, plagas, condiciones ideales) y el segundo sería una ficha de cada una de mis macetas donde ir registrando eventos (riego, poda, abono, fotos, por ejemplo).
Con el tiempo debería poder escalar, y añadir otras funcionalidades, como alertas (si hace más de x días enviar una alerta por telegram, por ejemplo) o incluso añadir monitorización (sondas de temperatura y humedad ambiental, sondas de humedad del suelo) o incluso automatizar el riego. Pero no nos adelantemos.
Vale, se entiende la idea, pero ¿qué vas a hacer?
Como ahora estoy tan metido en el mundo de los microservicios, había pensado lo siguiente:
Un frontend, con vue.
De momento aquí no innovamos nada.
Un BFF.
Esto no me convencía al principio, pero quería evitar que el frontend conociese qué micros existen. Luego desarrollo.
Microservicios para cada agregado.
Especies, especímenes, riego…
Pero la cosa al final no ha sido tan sencilla. Vamos por partes.
El frontend
Aquí he innovado un poco usando NaiveUI, no quería nada complicado y la verdad es que el frontend no me gusta. Para generar las vistas he tirado de copilot y vibe coding de ese. Me ha hecho un churro que ya veremos luego quien toca. Pero está vistoso. Yo le he dado el modelo de datos —a esto iremos luego— y a partir de ahí me ha generado unas vistas.
Aquí la idea (que ya había tonteado con ella en otra aplicación) era hacerlo offline-first, es decir, opero sin conexión y se sincronizan los datos más adelante. Para ello se guarda todo en IndexedDB y las operaciones en una cola que se procesa cuando haya conexión a la red. Esta última parte tengo que razonar cómo la hago todavía.
El caso es que estas operaciones se enviarían a una API, pero tenía sentido enviar un objeto operación a una misma API y que esta se encargase de decidir a qué micro iba, por lo que hacer usar nginx de proxy no era la mejor idea y mejor usar un BFF que se encargase de redirigir a cada micro.
Modelo de datos
Claro, había que crear y documentar el domain model, así que creé un repo sólo para documentación y diagramas con plantUML.
Lo de forgejo
Pequeño inciso, como los repos gratuitos suelen ir limitados de espacio (1 GB tengo en bitbucket) decidí instalarme una instancia de Forgejo en mi minipc. Así que estoy creando repos como si me pagasen por ello.
Nada, como decía, aquí estoy documentando un poco el modelo de datos, y tengo algún diagrama de componentes.
¿Y cómo configuras nginx?
Pues como tengo forgejo y crear repos es poco más de un click, me creé uno para infraestrutura. IaC hasta la médula.
En este repo me he creado un proyecto de ansible, para cargar las configuraciones de nginx para el front y el back, los micros se leen desde un fichero en yml, y aparte se configura el dns que tengo en otra raspberry distinta.
Más adelante meteré las configuraciones de las bases de datos o lo que sea necesario.
El BFF
Aquí tenía dos alternativas: configurar en nginx o crear un bff ad hoc. Todavía no tengo claro por qué descarté nginx, salvo por la posibilidad de añadir un nuevo frontend. La idea es utilizar este bff para la aplicación de jardinería, y añadir uno nuevo más adelante para una aplicación de agricultura. Bueno, proyectos futuros. Y además filtrar el resto de endpoints de los micros. 2
Las APIs
Pasear las especificaciones OpenApi entre micros lleva siempre a error. En general copiar y pegar código siempre lleva a error, y más si no hay un flujo claro y una propiedad clara del código. ¿Qué versión es la buena? ¿La del micro Y o la del micro Z?
A esto le di bastantes vueltas, porque ninguna acababa de convencerme. Por supuesto antes de pensar nada me creé un repositorio para las APIs. La idea era centralizar todos los contratos en un mismo punto.
La primera idea era, o la que había conocido yo, crear una especificación OpenAPI y a partir de ahí generar un cliente y un servidor. Después cada proyecto los importaba y usaba.
Pues nada, monté una pipeline de forgejo que usaba OpenAPI generator para crear un cliente para Vue y un servidor para spring.
Interludio II: docker
Soy una persona impaciente. Y cada vez que lanzaba una pipeline para generar cliente y servidor, me angustiaba que la mayor parte del tiempo se perdiese en instalar Maven y Node. Así que lo habéis adivinado. Tengo otro repo de forgejo con imágenes de docker ya preparadas. Según la necesidad. Luego en cada pipeline le indico a forgejo qué imagen debe usar.
Ahora volvamos a las APIs…
El caso concreto que conocía trabajaba sobre un stack concreto. Los clientes siempre eran A y los servidores B. ¿Pero qué pasa en mi caso? Habrá clientes Vue para el frontend. Pero también habrá clientes para Spring. Y me entró el gusanillo de Quarkus. Y ahí se complicó un poco la cosa. ¿Cuántos clientes tenía que generar? ¿Cuántos servidores? Me peleé un poco para que fuese configurable según cada OAS, pero ya insistiendo un poco en Quarkus vi que tiene su propia forma de generar clientes y servidores.
Quizás cada componente debería ser responsable de su propia implementación del adaptador. Así que le di un par de vueltas. El artefacto que iba a generar ese repositorio iba a ser únicamente el yaml. Uno para npm, otro para Maven. Y ahí ya cada micro o el frontend lo agrega como dependencia y genera lo que sea.
Así que en gradle, por ejemplo, he generado una tarea que extrae el yaml de la dependencia y lo copia en la carpeta resources. Y ya luego se generan las clases del controlador y demás.
Especies
Este es el más sencillo, y el único que está finiquitado. La idea es tener un micro que únicamente sirva de repositorio de información sobre las distintas especies.
La verdad es que no tiene mucho: se lee información, se devuelve.
Aquí lo único que podría haber tenido algo de miga era usar mongo para guardar cada especie como un documento. Pero el minipc sólo admite una versión antigua de mongo, y no montar una base de datos para eso me parecía una barbaridad. Y como yo no tengo que justificar el sueldo de ningún DBA, pues decidí que los datos iban a estar en memoria.
Cada documento no es excesivamente grande. Y no van a cambiar mucho, así que básicamente meto en la carpeta resources cada una de las especies que me interesen en YAML. Al arranque de la aplicación se leen y se monta un repositorio con un Map<EspecieId, Especie>.
Sí, tengo que desplegar cada vez que quiero añadir una especie, pero no tengo tantas. La idea a futuro es quizás meterlos en disco, y que de vez en cuando se lea y se actualice el repo. Ya veremos.
Y hablando de desplegar…
Bueno, me estuve peleando con forgejo y al final el proceso es el siguiente:
- Cuando se crea un tag en git, se lanza una pipeline de forgejo.
- Se pasan los tests, se llama a sonar, y si todo va bien compilamos a nativo.
- El resultado se publica como release de forgejo con la versión del tag.
- Una vez generado el ejecutable, con ansible tengo un playbook que descarga el ejecutable en el minipc, genera el servicio, y lo arranca.
No es ni CI ni CD. Pero estoy yo solo. No uso ramas, hago TBD y subo todo directamente a master. Sólo se generan los ejecutables cuando subo creo una etiqueta. Y en el mismo repo en el que tengo los playbooks para el resto de infraestructura, tengo uno por cada micro, que hace lo arriba comentado. Un poco manual todo, pero insisto, es un proyecto personal.
En resumen
- Un repo para frontend
- Otro para ansible
- Especificaciones OpenAPI
- Documentación
- Micros
- Imágenes docker
Próximos pasos
Seguiré con el micro de especímenes, que sí que tendrá algo más de chicha. Eventsourcing, DDD esas cosas y si tiene alguna curiosidad pues pondré algo de código o algún UML. Lo siguiente será otro micro para calcular cuándo se debe regar cada planta. Esas cosas. Si sigo haciendo CRUDs me consumirá el hastío.