Qué estamos haciendo (III)
Una complejidad inimaginable. Línea de luz clasificadas en el no-espacio de la mente, conglomerados y constelaciones de información. Como las luces de una ciuddad que se aleja...
¿Por dónde íbamos?
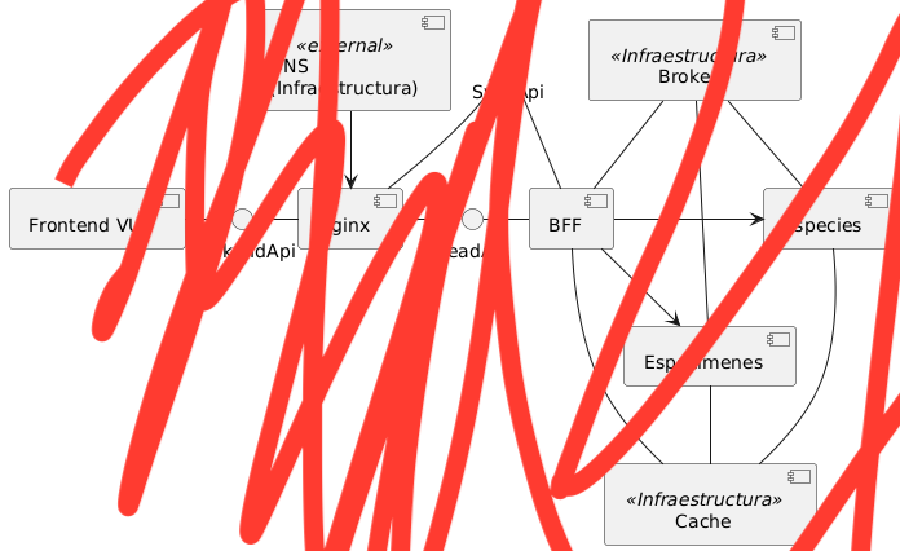
Estoy cansado. Pero recapitulemos. Estábamos enfrascados en una aplicación para la gestión del jardín. Un repositorio de especies, que había terminado cuando escribí la última entrada, y estaba preparando el microsevicio que gestionaría el estado de cada una de las plantas que tengo.
La idea es sencilla: desde el frontend se pueden realizar una serie de acciones sobre una planta concreta: crear, regar, podar, trasplantar, tratar. Estos comandos se almacenan en local hasta que hay conexión, y se envía un batch que se procesa en el micro de plantas.
Hasta aquí, todo es sencillo. Y bastante entretenido. En la entidad planta estos comandos se validan y se generan eventos de dominio. Estos eventos se usan para modificar el estado interno de la entidad. Event sourcing clásico.
public void tratar(
LocalDateTime cuando, String observaciones, TipoProducto tipoProducto,
String producto, BigDecimal cantidad, ModoAplicacion modoAplicacion
) throws PlantaException {
validarCreada();
registrar(new PlantaTratada(id, cuando, observaciones, tipoProducto, producto, cantidad, modoAplicacion));
}
private void registrar(PlantaEvent evento) throws PlantaException {
apply(evento);
domainEvents.add(evento);
version++;
}
public static Planta rehidratar(List<? extends PlantaEvent> historial) throws PlantaException {
if (historial == null) {
throw new PlantaException("El historial de eventos no puede ser nulo");
}
Planta planta = new Planta();
for (PlantaEvent evento : historial) {
planta.apply(evento);
planta.version++;
}
return planta;
}
private void apply(PlantaEvent evento) throws PlantaException {
switch (evento) {
case PlantaCreada e -> apply(e);
case PlantaRegada e -> apply(e);
case PlantaPodada e -> apply(e);
case PlantaTrasplantada e -> apply(e);
case PlantaTratada e -> apply(e);
case PlantaEstadioTransicionado e -> apply(e);
case null -> throw new PlantaException("El evento no puede ser nulo");
default -> throw new PlantaException("Evento de planta no soportado: " + evento.getClass().getSimpleName());
}
}
private void apply(PlantaRegada evento) throws PlantaException {
validarEventoDeLaPlanta(evento.plantaId());
this.ultimoRiego = new Riego(evento.cuando(), evento.observaciones());
}
No tiene mucho misterio. Además, al guardar cada evento, luego puedo crear una proyección para mostrar en el frontend el timeline de la planta.
Los comandos de la planta llegan, como comentaba, en un batch. Este batch se persiste en base de datos y se devuelve su identificador al frontend.1 Además, se lanza un evento de aplicación con ese identificador, en este caso usando VertX.
Un manejador de eventos recibe el mensaje y ya procesa el batch. Se agrupan por planta los comandos de cada planta, y cada comando se lanza en una transacción diferente para evitar que un fallo en una planta fastidie el resto. También metí un scheduler para reintentar el procesamiento por si hubiese un fallo puntual.
Aquí no voy a mostrar el código porque no está todo lo elegante que me gustaría. Y porque tampoco aporta demasiado para este punto.
Además, luego le metí observabilidad, y tengo un panel de Grafana que me muestra logs, las métricas del micro, errores de procesamiento.
Pero la entrada no iba de esto
Más allá del código, en esta entrada quería desarrollar algunas ideas que han ido cruzando mi mente a lo largo de estas últimas semanas. A priori no me dejan en buen lugar, pero creo que es importante hacer autocrítica en el proceso de mejora. Y también creo que es importante expresarlo en esta atmósfera de positividad asfixiante que respiramos en internet. Nadie pone en LinkedIn que ha elegido mal un trabajo o formación, no sea que. Nadie sube una foto fea a Instagram, no sea que. Me apena un poco que LinkedIn tenga una opción para celebrar logros, pero no fracasos, vaya.
Tampoco quiero extenderme en el problema de la mercantilización de nuestra imagen en redes, así que vamos a entrar en faena.
Forgejo
Creo que fue un acierto instalarme Forgejo en el Mini PC. Me ha dado libertad para crear todos los repos que quería, no dependo de que el día de mañana Bitbucket me cierre la cuenta, pero no puedo publicar los repos para que veáis el código. Podría, en realidad, pero no quiero exponer más cosas a internet en una máquina que tengo alojada en mi casa.
Está bien tener un repositorio de artefactos y de releases. Pero, por la ilusión del juguetito nuevo, me empeñé en usar las Forgejo Actions en lugar de Jenkins y creo que, en algunos aspectos, me ha jugado en contra respecto a lo que podría haber conseguido con Jenkins. Por ejemplo, no he encontrado una integración con Sonar decente, así que, si falla algo, me toca abrir Sonar y averiguar por qué. O la cobertura de JaCoCo. Y no acabé de buscar una forma de desplegar automáticamente.
No es de las peores decisiones, porque insisto, estoy bastante contento con la herramienta, pero quizás tener todo el CI/CD en Jenkins me habría resultado más cómodo.
CI/CD
Como consecuencia del punto anterior, por simplicidad y porque, al fin y al cabo, era un entorno personal, decidí hacer los despliegues manuales usando Ansible. Pensé que me daría cierto control poder elegir qué desplegaba. Y fue, claramente, un error. Ahora mismo hago un push y me quedo mirando durante 15 minutos cómo compila a nativo el ejecutable. Y ya entonces abro el proyecto de infra y lanzo el comando que me despliega el micro que toca. Todavía no me he visto en ninguna situación en la que no necesite desplegar tras compilar.
Falta de conocimiento del dominio
Conforme he ido modelando el dominio me he dado cuenta de lo poco que sé de cuidar plantas. Tanto que se me han muerto un romero y una albahaca. Tendría que haberme documentado quizás antes. De tener las plantas, digo.
Esto no es especialmente grave, porque sé que el modelo tiene que evolucionar con el tiempo. Pero vaya, que la prioridad de todo esto era ayudar a cuidar las plantas, y claramente no sé qué cuidados necesitan.
Falta de utilidad
De momento, la aplicación no es más útil que la libreta que tengo en la que voy apuntando observaciones y tratamientos de cada planta. Tampoco el repositorio de especies, porque no le he dedicado tiempo a rellenar la ficha de cada especie. Entiendo que no hago esto por la utilidad que pueda tener, pero sigo dándole vueltas a si hace falta dedicar tanto tiempo a algo que puede resolverse con papel y boli. Entiendo que más
Falta de planificación
En otros proyectos personales, tenía un tablero de Taiga en el que iba descomponiendo el proyecto en épicas, historias de usuario, tareas. Y hacía cambios incrementales. Poco a poco. Hacía algo, probaba, pasaba al siguiente.
Aquí he ido un poco a mi bola. Primero, el modelo de dominio entero. Luego, la especificación OpenAPI completa. Y el frontend, todo de golpe al final. Como es un proyecto personal puedo relajarme un poco. Mentira cochina: hay que ver antes de hacer. Y no tirarse dos días depurando la aplicación porque no sabes qué comandos están fallando por una particularidad de la compilación a nativo de Quarkus, o tener que rehacer frontend y backend porque, con todo montado, te has dado cuenta de que no has incluido el comando crear.
APIs
Este punto creo que es especialmente grave. En un proyecto en el que estuve, había un repositorio para la especificación OpenAPI de cada servicio. A partir de esta especificación se generaban cliente y servidor, y luego esas dependencias se importaban desde el frontend o desde el backend. Y me pareció una idea buenísima, así que intenté aplicarla aquí. Hasta aquí todo bien.
El problema fue aplicarla a mi caso. Como dije en la entrada anterior, empecé con esa idea, pero acabé produciendo como artefacto únicamente la especificación. Principalmente porque una misma especificación podía usarse como cliente tanto en el frontend como en microservicios. Y no sabía si los microservicios iban a ser Spring, Quarkus, Django o vaya usted a saber qué. En el proyecto en el que estaba, el cliente iba a ser siempre un frontend con un stack concreto y el servidor un backend con un stack concreto. Y además estaba mejor montado y con unas pipelines bastante más depuradas.
Ahora mismo, cada vez que quiero hacer un cambio en la API tengo que tocar el repo de las APIs, publicar, abrir los otros dos proyectos, actualizar dependencias y desplegar ambos. Y encima hay particularidades del generador de Quarkus para las que tengo que modificar la especificación en ese proyecto.
Quizás hubiese sido más sencillo que quien expone la API fuese el propietario, y copiar los cambios a mano. En un entorno más grande, con más desarrolladores y mejor infraestructura, no me parecería una buena opción, pero en mi caso ha sido claramente sobreingeniería.
Microservicios
Siempre abogo por monolith first porque siempre es más fácil descomponer en microservicios, si se hace bien. Pero tenía reciente la lectura del libro de Sam Newman2, y quería aplicar muchas cosas. Sin embargo, siendo una única persona y sin tener necesidades reales de escalado, hubiese tenido más sentido hacer un monolito modular.
Tengo sólo dos microservicios y para probar la aplicación en local tengo que tener tres proyectos abiertos. Y cuando tenga más, va a ser más complicado. Y de momento no tengo comunicación entre micros, pero más adelante hará falta y quizás sea más fácil hacerlo usando el bus de eventos de Quarkus. Así que quizás ese sea el próximo paso en el proyecto. Además reduciría mucha configuración y código repetido entre micros. No siempre hace falta instalar Kafka.
Próximos pasos
Por recapitular un poco, quizás el siguiente punto, antes de que crezca más la aplicación, será meter todo el backend en un mismo proyecto para simplificar el desarrollo. Y quizá acabar con el repositorio de APIs. Veremos si es posible separar en varios módulos de Gradle, uno para configuración general de Gradle y luego otros con cada bounded context. Todo con unos buenos test de ArchUnit para mantener una buena separación.
Y preparar un buen panel de Taiga o similar para tener el desarrollo más o menos organizado y no solo en mi cabeza.
Y el siguiente paso será ya pulir el módulo de plantas, y empezar con el módulo de notificaciones de riego, aunque probablemente haya uno únicamente de notificaciones y otro para calcular el riego y lanzar los eventos cuando sea pertinente. Quizás jugar con Telegram para recibir las notificaciones, aún no tengo claro cómo hacerlo al final.
Una especie de patrón Outbox, pero no del todo. ↩︎
Building Microservices, 2nd ed, Sam Newman. ↩︎